出典
概要
現状の自動運転はPerception, Prediction, Planningといったモジュール化されたタスクに分解して実現することが多いが、これだと情報伝達のインターフェース部分で情報が落ちてしまう。この論文では、ある程度モジュール化はしつつ、それらをTransformerでいうところのクエリで接続することでEnd-to-end気味なアーキテクチャとしたUniADを提案する。
UniADの立ち位置
まずPerception, Prediction, Planningといったモジュールの分け方について分類すると以下のようになる。

UniADはニューラネットワーク的にEnd-to-endでありながら、ちゃんとモジュール化もされて、それらがある程度もっともらしい構造で接続されているという点に新規性・優位性がある。
UniADの詳細
以下の図がだいたい全て。Backboneと、4つのTransformerによるモジュールと、1つのPlannerから構成される。

クエリで情報伝達をしていくというところが要点
Backbone
BEVFormerの学習済みモデルを使う。BEV空間の特徴量が得られるならば他のものでも良い。
参考文献
TrackFormer
クエリ(学習可能な埋め込み)をもとに、BEV特徴量Bにかけて物体をトラッキングする。
- 初期化クエリ : 今フレームで初めて検出されるものがあるかの検出を担当する
- トラッククエリ : 前フレームで検出されたエージェントを今フレームでもまた検出する
- 自車クエリ
| Notation | Shape and Params | Description |
|---|---|---|
| dynamic | number of agents from TrackFormer | |
| agent features from TrackFormer | ||
| agent positions from TrackFormer | ||
| layers | 6 | number of transformer decoder layers for TrackFormer |
参考文献
- [8] : End-to-End Object Detection with Transformers
- [100] : MOTR: End-to-End Multiple-Object Tracking with Transformer
- [104] : MUTR3D: A Multi-camera Tracking Framework via 3D-to-2D Queries
- [109] : Deformable DETR: Deformable Transformers for End-to-End Object Detection
MapFormer
lanes, dividers and crossings as things, and the drivable area as stuffを検出する。学習では全ての層に対して教師あり学習をして、推論時は最終層の出力のみを使う。
| Notation | Shape and Params | Description |
|---|---|---|
| 300 | number of map queries from MapFormer | |
| agent features from MapFormer | ||
| layers1 | 6 | number of transformer decoder layers for MapFormer |
| layers2 | 4 | number of mask decoder layers for MapFormer |
参考文献
- [50] : Panoptic Segmentation
- [56] : Panoptic SegFormer: Delving Deeper into Panoptic Segmentation with Transformers
MotionFormer

エージェントごとの軌跡を予測する。各エージェント個別で予測するのではなく、共同でいっぺんに予測する。トップkの軌跡をscene-centric mannerで予測する。エージェントについて、
個の、
タイムステップにおける
座標を予測するので、つまり
個のfloatが出てくる。
ここで使うトランスフォーマーは若干特殊で、3種類の相互作用agent-agent, agent-map, agent-goalを考慮する。Self-AttentionとCross-Attention、およびagent-goalに関してはDeformable Attentionを使ってごちゃごちゃと求めている。
ここでは前層の予測軌跡の最終点で、DeformableAttnはその周りでBについて情報を取得する感じになる。
を連結してMLPにかけて
にし、次の層に入力される。入力されるときには、クエリ位置に関する
を和算する。
は
以下の部分はよくわからなかった。
The scene-level anchor represents prior movement statistics in a global view, while the agent-level anchor captures the possible intention in the local coordinate. They are both clustered by k-means algorithm on the endpoints of groundtruth trajectories, to narrow down the uncertainty of prediction. Contrary to the prior knowledge, the start point provides customized positional embedding for each agent, and the predicted endpoint serves as a dynamic anchor optimized layer-by-layer in a coarse-to-fine fashion.
学習中には軌道を滑らかにするような処理を入れるともあったが、ここもハッキリとわかるわけではなかった。
| Notation | Shape and Params | Description |
|---|---|---|
| 6 | number of forecasting modality in MotionFormer | |
| 12 | length of prediction timestamps in MotionFormer | |
| layers | 3 | number of transformer decoder layers for MotionFormer |
| |
query position in MotionFormer | |
| |
query context in MotionFormer | |
| |
motion query after agent-agent interaction in MotionFormer | |
| |
motion query after agent-map interaction in MotionFormer | |
| |
motion query after agent-goal point interaction in MotionFormer | |
| |
scene-level anchor position in MotionFormer | |
| |
agent-level anchor position in MotionFormer |
参考文献
- [43] : Multi-Agent Trajectory Prediction by Combining Egocentric and Allocentric Views
- [44] : HDGT: Heterogeneous Driving Graph Transformer for Multi-Agent Trajectory Prediction via Scene Encoding
- [63] : Multimodal Motion Prediction with Stacked Transformers
- [69] : Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
- [70] : Scene Transformer: A unified architecture for predicting multiple agent trajectories
- [84] : Motion Transformer with Global Intention Localization and Local Movement Refinement
- [99] : AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecasting
OccFormer
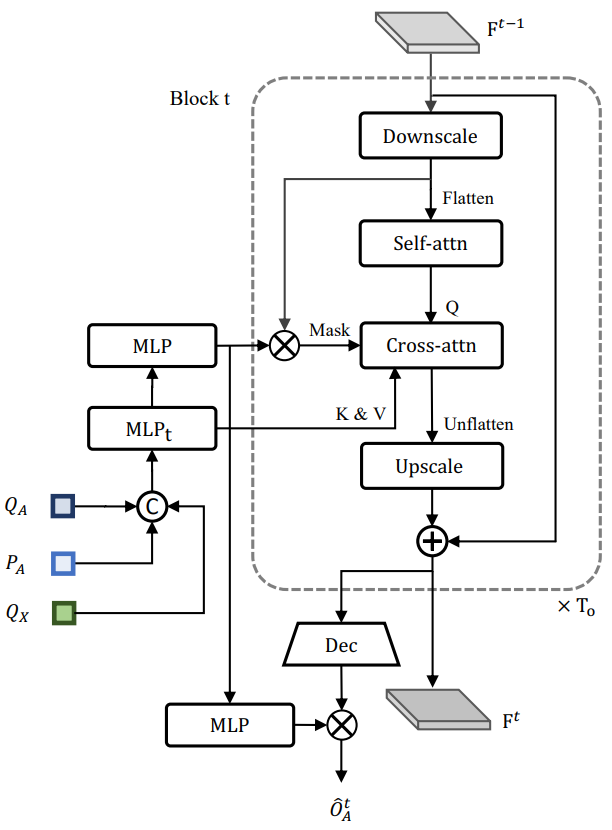
将来の占有率を予測する。1ブロックで1タイムステップ分を予測をする。
入力としてはTrackFormerの出力と、位置エンコーディング
及び、MotionFormerの出力を最大プーリングで圧縮したもの
をMLPにかけて計算する。最初のブロックにはBEV特徴量Bも1/4サイズにダウンスケールして入力する。
各ブロックでは途中で一度ダウンスケールして出力前で元のサイズに戻すということをする。そのダウンスケールした状態で先のエージェント特徴量とのAttentionを計算する。そのときにマスクとしてそのピクセルのエージェントに関するものだけAttentionを張るようにする。
最終ブロックから出てくると、エージェント特徴から計算できる
を掛け合わせてもとめる。
| Notation | Shape and Params | Description |
|---|---|---|
| 5 | length of prediction timestamps in OccFormer | |
| agent feature input | ||
| future state output | ||
| motion query (max-pooled on modality level) from the last layer of MotionFormer | ||
| |
downscaled dense feature | |
| |
decoded dense feature after convolutional decoder | |
| |
agent-aware dense feature after pixel-agent interaction | |
| |
instance-level probability map | |
| |
classical instance-agnostic occupancy map merged from |
|
| |
attention mask for pixel-agent interaction | |
| mask feature | ||
| occupancy feature |
Planner

進むべき方向を示すコマンド(左折・右折・直進)を、コマンド埋め込みに変換する。これとBEV特徴量から軌跡を予測し、OccupancyMapの占有率で確率の高いところは避けるように最適化する。
| Notation | Shape and Params | Description |
|---|---|---|
| layers | 3 | number of transformer decoder layers for Planner |
| 6 | length of planning timestamps in Planner |
参考文献
- [11] : MP3: A Unified Model to Map, Perceive, Predict and Plan
- [38] : ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning
学習方法
2段階で学習する。まずTrackingとMappingのところを6エポック学習させ、次に全体を20エポックで学習させる。
実験
使用データセット : nuScenes
切除実験
UniADの各パーツを切除して学習実験をしたところ、表のような結果になった。多くのモジュールが入っているNo.9やNo.12で良い結果が出ていることから、共同学習が各モジュールの学習を促進していることがわかる。

とはいえ、Trackingの性能などはこれくらいの数値的な向上でどれくらい実際の性能が変わるのかはよくわからない。Planningもこれだけのモジュールを動かのに見合った向上量なのだろうか。
各モジュール特化の既存手法との比較
Object Trackingや、Online MappingといったPerceptionに関するそれぞれの手法に特化した既存手法と比べると、UniADは劣っているところもある。とはいえUniADはPlanningに焦点を当てた手法であり、PredictionとPlanningについては既存手法よりも良い指標を出している。
可視化結果

所感
もしかしたらこういった手法がデファクトスタンダードになっていく可能性がなくはないとはいえ、こんなに複雑なニューラルネットワーク・パズルゲームはしんどいなという気持ちになる。もっとシンプルにならないんだろうか。
行ってほしい方向をコマンドで指定するというところも、実運用的にどうなるのかがイマイチ上手く想像ができなかった。そのコマンドを発行するのはどういうモジュールになるんだろうか。コマンド発行のためには自己位置とかマップが別に必要になってしまうんだろうか。その精度はどの程度必要になるんだろうか。
この論文が主張する通りなら、もしTrackingしかしないとしても後続タスクまで学習させた方が良いということになるので、ますますデータの集め方・取り扱い方が重要になっていくような気がする。いろんなものを一括で学習できるようなデータになっていないといけない。
なんか若干違うんじゃないかという気はしつつ、上手くいくならば納得できない手法でもなんでもやらなきゃいけないので、とりあえずは選択肢として念頭に置いておくということで。